定义函数
协处理器注释
@coprocessor 注释指定一个 python 函数作为 GreptimeDB 的协处理器,并为其设置一些属性。
该引擎允许一个且仅有一个用 @coprocessor 注释的函数,不能在一个脚本中拥有一个以上的协处理器。
| Parameter | Description | Example |
|---|---|---|
sql | Optional. The SQL statement that the coprocessor function will query data from the database and assign them to input args. | @copr(sql="select * from cpu", ..) |
args | Optional. The argument names that the coprocessor function will be taken as input, which are the columns in query results by sql. | @copr(args=["cpu", "mem"], ..) |
returns | The column names that the coprocessor function will return. The Coprocessor Engine uses it to generate the output schema. | @copr(returns=["add", "sub", "mul", "div"], ..) |
backend | Optional. The coprocessor function will run on available engines like rspy and pyo3, which are associated with RustPython Backend and CPython Backend respectively. The default engine is set to rspy. | @copr(backend="rspy", ..) |
sql 和 args 都是可选的;它们必须都可用,或都不可用,并通常在后查询处理中被使用,详情请阅读下文。
returns 是每个 coprocessor 都需要的,因为输出模式必然存在。
因为 RustPython 不能支持 C 语言 API,当尝试使用 pyo3 后端来使用只支持 C 语言 API 的第三方 python 库时,例如 numpy,pandas 等,backend 则是必要的。
协处理器函数的输入
该协处理器也接受之前已经看到的参数:
@coprocessor(args=["number"], sql="select number from numbers limit 20", returns=["value"])
def normalize(v) -> vector[i64]:
return [normalize0(x) for x in v]
参数 v 是执行 sql 返回的查询结果中的 number 列(由 args 属性指定)。
当然,也可以有多个参数:
@coprocessor(args=["number", "number", "number"],
sql="select number from numbers limit 5",
returns=["value"])
def normalize(n1, n2, n3) -> vector[i64]:
# returns [0,1,8,27,64]
return n1 * n2 * n3
除了 args,还可以向协处理器传递用户定义的参数:
@coprocessor(returns=['value'])
def add(**params) -> vector[i64]:
a = params['a']
b = params['b']
return int(a) + int(b)
然后从 HTTP API 传递 a 和 b:
curl -XPOST \
"http://localhost:4000/v1/run-script?name=add&db=public&a=42&b=99"
{
"code": 0,
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "value",
"data_type": "Int64"
}
]
},
"rows": [
[
141
]
]
}
}
],
"execution_time_ms": 0
}
将 a=42&b=99 作为查询参数传入HTTP API,返回结果 141。
用户定义的参数必须由协处理器中的 **kwargs 来完成,其类型都是字符串。可以传递任何想要的东西,如在协处理器中运行的 SQL。
协处理器函数的输出
正如前面的例子所展示的那样,协处理器函数的输出必须是向量。
We can return multi vectors:
from greptime import vector
@coprocessor(returns=["a", "b", "c"])
def return_vectors() -> (vector[i64], vector[str], vector[f64]):
a = vector([1, 2, 3])
b = vector(["a", "b", "c"])
c = vector([42.0, 43.0, 44.0])
return a, b, c
函数 return_vectors 的返回类型是 (vector[i64], vector[str], vector[f64])。
但必须确保所有这些由函数返回的向量具有相同的长度,因为当它们被转换为行时,每一行必须呈现所有的列值。
当然,可以返回字面值,它们也会被转化为向量:
from greptime import vector
@coprocessor(returns=["a", "b", "c"])
def return_vectors() -> (vector[i64], vector[str], vector[i64]):
a = 1
b = "Hello, GreptimeDB!"
c = 42
return a, b, c
HTTP API
/scripts 提交一个 Python 脚本到 GreptimeDB。
保存一个 Python 脚本,如 test.py:
@coprocessor(args = ["number"],
returns = [ "number" ],
sql = "select number from numbers limit 5")
def square(number) -> vector[i64]:
return number * 2
将其提交到数据库:
curl --data-binary @test.py -XPOST \
"http://localhost:4000/v1/scripts?db=default&name=square"
{"code":0}
Python 脚本被插入到 scripts 表中并被自动编译:
curl -G http://localhost:4000/v1/sql --data-urlencode "sql=select * from scripts"
{
"code": 0,
"output": [{
"records": {
"schema": {
"column_schemas": [
{
"name": "schema",
"data_type": "String"
},
{
"name": "name",
"data_type": "String"
},
{
"name": "script",
"data_type": "String"
},
{
"name": "engine",
"data_type": "String"
},
{
"name": "timestamp",
"data_type": "TimestampMillisecond"
},
{
"name": "gmt_created",
"data_type": "TimestampMillisecond"
},
{
"name": "gmt_modified",
"data_type": "TimestampMillisecond"
}
]
},
"rows": [
[
"default",
"square",
"@coprocessor(args = [\"number\"],\n returns = [ \"number\" ],\n sql = \"select number from numbers\")\ndef square(number):\n return number * 2\n",
"python",
0,
1676032587204,
1676032587204
]
]
}
}],
"execution_time_ms": 4
}
也可以通过 /run-script 执行脚本:
curl -XPOST -G "http://localhost:4000/v1/run-script?db=default&name=square"
{
"code": 0,
"output": [{
"records": {
"schema": {
"column_schemas": [
{
"name": "number",
"data_type": "Float64"
}
]
},
"rows": [
[
0
],
[
2
],
[
4
],
[
6
],
[
8
]
]
}
}],
"execution_time_ms": 8
}
Python 脚本的参数和结果
/scripts 接受指定数据库的查询参数 db,以及命名脚本的 name。/scripts 处理 POST 方法主体来作为脚本文件内容。
/run-script 通过 db 和 name 运行编译好的脚本,然后返回输出,这与 /sql API 中的查询结果相同。
/run-script 也接收其他查询参数,作为传递到协处理器的用户参数,参考输入和输出。
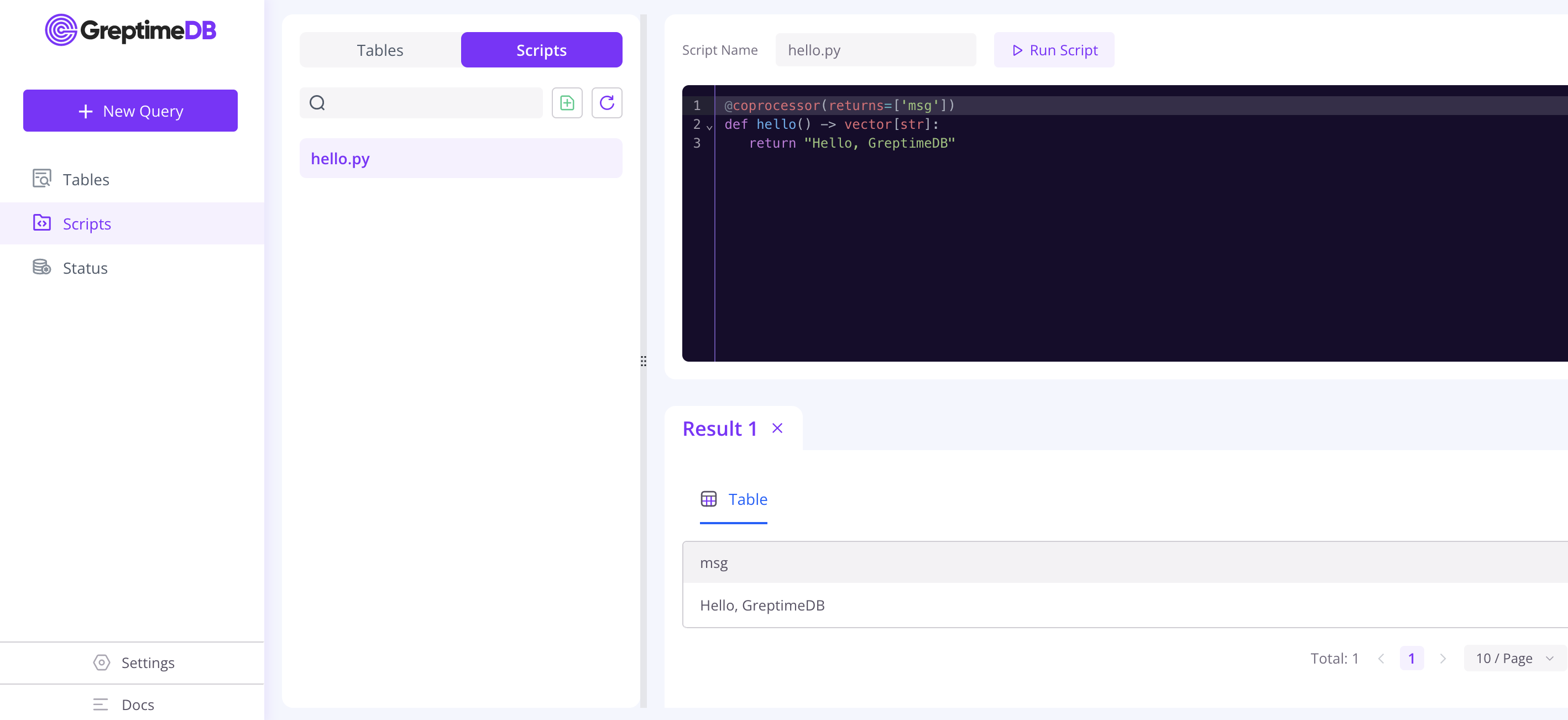
在 GreptimeDB 控制台中编辑脚本
GreptimeDB 控制台 提供了编辑器供用户方便地编辑脚本。
在启动 GreptimeDB 后,你可以通过 URL http://localhost:4000/dashboard 访问控制台。
点击左侧边栏的 Scripts 进入脚本列表页。
你可以创建一个新的脚本,编辑一个已有的脚本,或者从控制台运行一个脚本。